RabbitMQ 는 Message Broker 로써 AMQP ( Advanced Message Queuing Protocol ) 기반으로 만들어졌는데, 이외에도 STOMP ( Simple Text Oriented Messaging Protocol ), MQTT ( Message Queuing Telemetry Transport ), HTTP 등 다양한 프로토콜을 지원한다. RabbitMQ 는 Documentation 으로 유명하다. 실제로 RabbitMQ 를 처음 접하는 개발자들이 궁금하거나 의아해할 수 있는 지점에서 예상했다는 듯 부연 설명, 예제 소스코드 등을 제시하고 있어 매우 쾌적하게 진입할 수 있다. 특정 기술을 분석함에 있어, 용어 정리는 필수이다. 이해를 위한 문서와 사람간에 프로토콜이랄까? RabbitMQ 에서 사용하는 Glossary 부터 정리하자.
Glossary
Message Broker
의미 그대로 메시지 브로커이다. 메시지를 받고, 보내는 역할을 하는 것이다.
Producer
메시지를 보내는 주체
Exchange
마치 네트워크 장비인 라우터를 Layer7 수준에서 구현한 것과 같다.
Routing Key 를 받아, 해당 Routing Key 로 Bind 처리된 Queue 로 메시지를 전달하는 주체.
Publish / Subscribe
Publish / Subscribe 패턴이다. 옵저버 패턴으로도 불린다. 말 그대로 메시지를 다양한 구독자에게 배포하는 행위를 말한다.
Queue
의미 그대로 큐 이름이 지정된 유니크한 큐이다.
Bindings
Queue 와 Exchange 의 관계를 뜻한다.
Consumer
Queue 로부터 메시지를 소화하는 주체이다.
Connection
추상화된 소켓 커넥션을 의미한다.
Channel
Connection 에서 만들어진 채널을 의미한다. 당연히 1 Connection 당 N 개의 Channel 을 가질 수 있다.
코드 관점에서 보면 Channel 객체에 RabbitMQ API 가 존재한다.
Basics
Queue 를 사용하는 이유?
메시지를 동일하지 않은 시스템으로 전달시키기 위해서다. 메시지는 다양한 형태일 수 있다. 단순한 문자열이거나, 특정 시스템의 OperationCode 이거나, HTTP Request 일 수도 있다. 또 메시지는 비동기 형태로 올 수 있다. 이때 메시지를 받아서 처리하는 App 이 각 종 이유에 의해서 동작이 멈춘 경우, Queue 에서 해당 Message 를 삭제하지 않고 보관하여 해당 메시지를 처리할 수 있는 App 이 Online 되는 즉시 다시 Queue 에서 메시지를 꺼내어 줄 수 있다는 장점이 생긴다. 그리고 하나의 HTTP Request Window 를 갖는 일반적인 Web Application 에서 Message Queue 를 통해서 효과적이고 빠르게 요청을 처리할 수 있다.
Round-Robin Dispatching
RabbitMQ 는 라운드로빈 방식으로 메시지를 전달한다. 아래 상황을 보면 무엇인지 쉽게 파악가능하다.
Queue 가 2개 존재하는 아래와 같은 상황을 상상해보자.
1. Producer 는 "1", "2", "3", "4", "5", "6", "7" 메시지를 Publish 했다.
2. Round robin dispatch 로 인하여 Queue_A 와 Queue_B 는 아래와 같이 메시지를 받게된다.
Queue_A got message "1"
Queue_A got message "3"
Queue_A got message "5"
Queue_A got message "7"
Queue_B got message "2"
Queue_B got message "4"
Queue_B got message "6"
Message Acknowledgement
기본적으로 RabbitMQ 는 Queue 에서 Consume 된 Message 를 곧바로 삭제 처리를 위해 마킹을 한다. 만약 해당 Message 를 Consume 한 Consumer 가 해당 메시지를 처리하다가 동작이 멈춰버리면, 해당 메시지는 유실되는 것이다. Queue 에 더 이상 남아있지 않기 때문이다.
그래서 Message Acknowledgement Option 이 준비되어 있다. Queue 에서 Consume 된 Message 는 삭제 마킹이 되지 않고, Unack 으로 마킹된다. 해당 Message 를 Consume 한 Consumer 가 해당 메시지를 잘 받았고, 잘 처리했다는 Ack 이벤트를 발생시켜야만, Unack 마킹에서 Delete 마킹으로 업데이트하여 Queue 에서 제거하도록 하는 것이다.
이를 통해 Queue 에서 제대로 처리되지 못 한 Message 가 유실되는 것을 방지할 수 있다.
No message timeout
RabbitMQ 에는 메시지 타임아웃이 존재하지 않는다. 다시 메시지를 보낼 뿐이다.
Message Durability
Message Acknowledgement 와 비슷한 메시지 백업 행위이다. 그러나 Message Acknowledgement 가 Consumer 가 메시지를 처리하는 도중 문제가 발생한 경우를 대비했다면, Durability 는 RabbitMQ Server 자체가 죽었을 경우를 대비한 것이다. Queue 를 생성할 때 Durable 옵션을 True 로 주어야 하며, 해당 Channel 에서 Persistent 속성을 True 로 주어야 RabbitMQ Server 가 죽었을 경우에도 Queue 에 쌓인 메시지를 복원할 수 있다.
Fair dispatch
말 그대로 공평하게 메시지를 분배한다는 것이다. RabbitMQ 는 Round robin 방식으로 메시지를 전달한다고 했다. 그러나 아래와 같은 상황에선, Round robin 이 상당히 문제의 소지가 있다.
1. Producer 는 5초마다 "1", "2", "3", "4", "5" ······ 메시지를 Publish 한다.
2. Round robin dispatch 로 인하여 Queue_A 와 Queue_B 는 번갈아가면서 메시지를 받게된다.
3. 그러나 Queue_A 에서 Message 를 Consume 하는 Consumer 가 한 메시지를 처리하는 데 매번 10초가 걸린다.
4. Queue_B 의 Consumer 는 메시지를 3초 안에 처리할 수 있다.
5. 결국 Queue_A 에 쌓이는 Message 는 시간이 갈 수록 늘어난다.
5초 경과
10초 경과
20초 경과
30초 경과
40초 경과
······
Queue_A
쌓인 MSG 1
처리 MSG 0
쌓인 MSG 1
처리 MSG 1
쌓인 MSG 2
처리 MSG 2
쌓인 MSG 3
처리 MSG 3
쌓인 MSG 4
처리 MSG 4
······
Queue_B
쌓인 MSG 0
처리 MSG 1
쌓인 MSG 0
처리 MSG 2
쌓인 MSG 0
처리 MSG 4
쌓인 MSG 0
처리 MSG 6
쌓인 MSG 0
처리 MSG 8
······
이를 방지하기 위해 basicQos 를 이용하여 prefetchCount 를 조절할 수 있다. prefetchCount 를 조절하면 해당 Queue 에 Unack 상태로 쌓여만 가는 메시지 수를 조절할 수 있어서, 해당 prefetchCount 임계점에 도달한 Queue 에는 메시지를 쌓지 않고 다음 Queue 에게 메시지를 쌓기 때문에, 공평하게 메시지를 분배할 수 있게 된다.
Basics+
Exchange
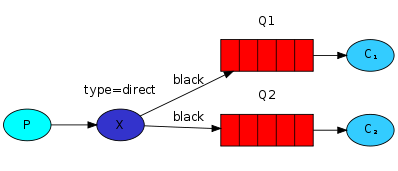
RabbitMQ 의 핵심 사상은 절대 메시지를 Queue 로 바로 전송하지 않는다는 것이다.
Producer 와 Queue 사이에 Middle Layer 로써 Exchange 가 존재하며, 도식은 아래와 같다.
Exchange 는 4가지 Type 을 갖고, Exchange 선언시 지정 가능하다.
- direct
- topic
- header
- fanout
Binding
Exchange 를 통해서 어떤 Queue 로 메시지를 라우팅 시킬 것인지 지정해야 한다. 이 행위를 Binding 이라고 부른다.
Binding 시에는 routingKey 라는 속성을 지정하게 되는데, 이것이 위 Exchange 4가지 타입을 활용하는 핵심이다.
Direct Exchange
RoutingKey 가 완전히 100% 매치될 때만, Exchange 에서 메시지를 해당 Queue 로 보내는 타입이다.
메시지의 RoutingKey 가 "orange" 인것은 Q1 으로만 전송되며, "black" 과 "green" 은 Q2 로 전송된다.
QueueBind 를 복수로 호출하여 한 Queue 에 여러가지 RoutingKey 를 등록시킬 수 있다.
각기 다른 Queue 에 동일한 RoutingKey 를 부여하여 MultiBindings 도 가능하다
Fanout Exchange
RoutingKey 에 상관없이, 모든 Queue 에 메시지를 보낸다. Fanout 은 "흩어지다" 라는 의미가 있고,
"가위 바위 보" 할 때 너무 가까이 붙어있으니 좀 떨어지자 할 때도 " Hey fan out! fan out! " 이라고 하기도 한다.
구글에 Fanout 이미지를 치면 이러한 SFP 케이블이 보인다. 무수하게 흩어지는 이 느낌, 그리고 메시지를 뿌리는 행위!
이것이 Fanout 이다.
Topic Exchange
Routing Key 로 Topic 을 갖는 타입이다. 특정 주제, 또는 제목 따위를 Key 로 갖겠다는 것이다.
모든 단어가 일치해야 하는 Direct Exchange 에 비해 와일드카드 ( *, # ) 를 이용해 훨씬 더 유연하게 구성할 수 있다.
* : 단어 하나로 대체될 수 있다.
# : 여러 개의 단어로 대체될 수 있다.
genius.orange.damon RoutingKey 는 Q1 로 간다.
you.orange.farm RoutingKey 도 Q1 로 간다.
apple.orange.mango RoutingKey 도 Q1 로 간다.
topic.exchange.rabbit RoutingKey 는 Q2 로 간다.
sample.example.rabbit RoutingKey 도 Q2 로 간다.
.
.
.
그러나 * 와일드 카드는 단어 한 개만 대체할 수 있기 때문에 genius.dm.tistory.orange.post 는 Q1 으로 갈 수 없다.
이럴 때 유용한 것이 # 와일드 카드이다.
lazy.rabbit RoutingKey 는 Q2 로 간다.
lazy.exchange.queue RoutingKey 도 Q2 로 간다.
lazy.company.department.employer RoutingKey 도 Q2 로 간다.
lazy.company.department.employer.sex.height ~~ RoutingKey 도 Q2 로 간다.
Header Exchange
RoutingKey 를 HTTP Header 와 같이 { Key : Value } 형태로 사용하고 싶을 때 쓸 수 있다. 이 Exchange 타입에서는 RoutingKey 가 무시되고, 오직 Header 의 속성인 X-match 만을 바라보고 라우팅을 수행하게 된다.
아래 두 가지 매칭 레벨을 지정할 수 있다.
- any : OR 조건이다. N 개의 { Key : Value } Header X-match 값 중 하나라도 일치하면, 해당 Queue 로 메시지를 보낸다.
- all : AND 조건이다. X-match 에 선언한 값 모두가 일치할 때 해당 Queue 로 메시지를 보낸다.
개인적으로 Topic Exchange 가 있기 때문에, Header Exchange 의 활용도는 사실상 매우 낮지 않을까 생각한다.
RPC
ReplyTo 속성에 응답 메시지를 받을 Queue 를 지정하는 것이 핵심이다. ReplyTo 속성은 Producer 가 메시지를 Publish 할 때 이 메시지에 대한 응답을 어느 Queue 로 받고 싶다고 지정하게 된다. 그러면 Consumer 는 해당 메시지를 받고, ReplyTo 속성이 있으면 해당 Queue 로 다시 Producer 처럼 Publish 를 하는 방식으로 동작한다.
Correlation Id
RPC 를 통해 응답메시지를 받을 때, ReplyTo 로 지정한 Queue 로 받게 되는데 이 때 어떤 Request 를 처리한 Response 인지 알기가 힘들다. 그래서 Message 를 Publish 할 때 마다 CorrelationId 를 GUID 로 생성하고, 이 값은 Response 메시지에 보관되어 전달된다. 이로써 클라이언트는 어떤 요청에 의한 응답인지 알 수 있다.
Basic Understanding
RabbitMQ is a message broker that was originally built on AMQP. Besides AMQP, it supports STOMP ( Simple Text Oriented Messaging Protocol ), MQTT ( Message Queuing Telemetry Transport ), HTTP protocols. RabbitMQ is a well-known for its documentation.
In fact, RabbitMQ newbies will be able to deploy RabbitMQ very easily with its excellent documentation and sample source codes. They are right there for you as if RabbitMQ developers had already expected that newbies would be lost at certain points.
Glossary
Message Broker
Literally, message broker. It receives messages and sends them back.
Producer
The one who sends (publishes) messages.
Exchange
It's like a physical network router on Layer7.
It gets a routing key and sends the message to a matched queue that expects to have messages with the right key.
Publish / Subscribe
It's Publish / Subscribe pattern. It's also called Observer pattern.
Queue
It's a queue, literally.
Bindings
It's a relationship between a queue and an exchange ( or exchanges and queues )
Consumer
It consumes messages from a queue.
Connection
It's an abstract socket connection.
Channel
It means a channel that has been made out of a connection. Ofcourse you can create several channels more in a single connection.
In code terms, Channel class got the whole RabbitMQ APIs.
Basics
What queue is for?
To deliver messages to different kind of systems. Messages themselves can be various things. It could be a HTTP request header form, just some text combinations, or some operation code for a system. Messages can be asynchronous. In asynchronous environment, a consumer who consumed a message from a queue dies with an unfortunate incidence, then the message can be re-queued again and the queue immediately sends it back to the consumer right after online status turns on. And this is especially effective in a web application that has only a HTTP request window.
Round-Robin Dispatching
RabbitMQ delivers message in round-robin way. Let's see the example below.
Assume that we have two queues.
1. Producer has published "1", "2", "3", "4", "5", "6", "7" messages.
2. As a result of round-robin dispatching, Queue_A and Queue_B are going to get messages respectively.
Queue_A got message "1"
Queue_A got message "3"
Queue_A got message "5"
Queue_A got message "7"
Queue_B got message "2"
Queue_B got message "4"
Queue_B got message "6"
Message Acknowledgement
Basically a queue marks a message for deletion that has been consumed by a customer. If the consumer dies before it processes the messages properly, then the message will be gone, nowhere either in the queue or the customer.
So here message acknowledgement option goes. If this option is turned on, a consumed message won't get a deletion mark, instead it gets an unack mark. This unack mark never fades away until the consumer fires BasicAck event. If the consumer dies, then the unack message will be requeued to the queue and be ready to be redelivered.
This way, you can prevent any message losses in this case.
No message timeout
RabbitMQ doesn't have any message timeout. It just redelivers them.
Message Durability
A similar backup behavior like message acknowledgement, but durability is for RabbitMQ server itself. Message acknowledgement options is for consumers, it doesn't guarantee the message backup when RabbitMQ server crashes. You have to set true to durable when you declare a queue and have to make sure to set true to persistent property in a channel. If not, it's going to recover the queue only, not the messages in it.
Fair dispatch
Literally it means dispatching messages faily. As I mentioned before, RabbitMQ delivers messages in round robin way. in below circumstances, round robin dispatching can be painful.
2. As a result of round-robin dispatching, Queue_A and Queue_B are going to get messages respectively.
3. But it takes 10 seconds for Queue_A to process a message.
4. It takes 3 seconds for Queue_B to process one.
5. Eventually and gradually, unprocessed messages ( Unack messages ) will be queued up high in Queue_A over and over again.
5 secs passed
10 secs passed
20 secs passed
30 secs passed
40 secs passed
······
Queue_A
Unack MSG 1
Acked MSG 0
Unack MSG 1
Acked MSG 1
Unack MSG 2
Acked MSG 2
Unack MSG 3
Acked MSG 3
Unack MSG 4
Acked MSG 4
······
Queue_B
Unack MSG 0
Acked MSG 1
Unack MSG 0
Acked MSG 2
Unack MSG 0
Acked MSG 4
Unack MSG 0
Acked MSG 6
Unack MSG 0
Acked MSG 8
······
To prevent this, you can set prefetchCount using basicQos. Setting prefetchCount will block additional messages coming into the slow queue once it reaches the limit. Then the blocked messages will be delivered to another available queue.
Basics+
Exchange
The core idea is to never send message directly to a queue.
An exchange exists as a middle layer between a producer and queues. Below is the diagram.
An exchange could have four types
- direct
- topic
- header
- fanout
Binding
You have to specify which exchanges you will use in order to route a message. This is called "binding".
A routing key must be set when you configure binding and this is the most important feature you should know to make the best of use of the four exchange types above.
Direct Exchange
In this scenario, a message will be delivered to a queue that exactly, 100% matches the routing key.
As the diagram says, a message with a routing key "orange" goes into Q1, and the others go into Q2.
You can set N routing keys to a queue by invoking QueueBind.
You can also set a same routing key to different queues. This is called "multi bindings"
Fanout Exchange
It's a mindless broadcasting, completely ignoring routing keys. When you google "fan out" you will get to see some of this.
Topic Exchange
In this scenario, you can have a topic as a routing key. Some specific titles or topics can be your routing key.
You can have more flexibility with topic exchange as opposed to direct exchange where you have to match the whole word to deliver a message, because topic exchange has two wild cards.
* : replace one word.
# : replace more than one word.
genius.orange.damon routing key goes to Q1.
you.orange.farm routing key also goes to Q1.
apple.orange.mango routing key goes to Q1.
topic.exchange.rabbit routing key goes to Q2.
sample.example.rabbit routing key goes to Q2.
.
.
.
But * wildcard can replace only one word, genius.dm.tistory.orange.post will not be able to go to Q1.
Here # wildcard comes out.
lazy.rabbit routing key goes Q2.
lazy.exchange.queue routing key also goes Q2.
lazy.company.department.employer routing key also can go to Q2.
lazy.company.department.employer.sex.height ~~ ( whatever ) routing key goes to Q2.
Header Exchange
You can use this when you want to use a routing key as { Key : Value } pair, just like a HTTP request header. In this scenario, the routing key will be completely ignored and exchanges will only inspect X-match property in the header and route the message accordingly.
You can set two options in the header.
- any : OR condition. One of the key-value pairs in X-match prop matches? then it's okay to send the message to the target queue.
- all : AND condition. All of the key-value pairs in X-match prop match? then it's okay to send the message to the target queue.
IMAO, topic exchange will be prevalent, who's going to use header exchange?
RPC
The core idea is to set a response queue name to reply_to property. You can set reply_to property, publishing a message. Then a consumer gets the msg and sends it back to the destination if reply_to exists.
Correlation Id
When you get a response message from the reply_to queue, you just don't know which request the response belongs. That's when this correlation id is used. Everytime you publish a message, you make a GUID value and set it to the correlation id. Then the property will live to the end of the message life cycle.