| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- esl
- .net
- identityserver3
- oauth2
- identityserver
- english
- C#
- slow in the application
- fast in ssms
- MSSQL
- IdentityServer4
- 저장프로시저
- SSMS
- async await
- execution plan
- await
- SQLServer
- async
- TPL
- Dataannotation
- stored procedure
- validation
- 쿼리 최적화
- SQL Server Optimizer
- ThreadPool
- task
- 느린 저장프로시저
- 영어공부
- 실행계획 원리
- query
- Today
- Total
shyaway
Slow in the Application, Fast in SSMS? Part 2 본문
Slow in the Application, Fast in SSMS? Part 2
쿼리 실행 계획을 캐싱하기
- SQL Server 의 버퍼 캐시가 모두 사용된 경우 SQL Server 는 한 동안 캐시에서 사용되지 않은 오래된 버퍼에 대한 삭제를 요하게 된다. 이 버퍼 캐시에는 실행 계획과 더불어 테이블 데이터도 포함된다.
- ALTER PROCEDURE 를 실행한 경우
- sp_recompile 을 실행한 경우
- 전체 실행 계획을 삭제하는 DBCC FREEPROCCACHE 를 실행한 경우
- SQL Server 가 재시작 한 경우. 캐시는 당연히 메모리이기 때문에 리스타트시 캐시가 유지될 수 없다.
- 구성 파라메터를 변경한 경우 ( sp_configure 나 SSMS 의 Server Properties pages 에서 ) 모든 실행 계획 캐시가 제거된다.
- 해당 쿼리에 명시된 테이블 정의를 변경할 시
- 쿼리에 명시된 특정 테이블의 인덱스를 추가하거나 제거할 시. ALTER INDEX 와 DBCC DBREINDEX 를 호출했을 경우도 동일함.
- 해당 쿼리에서 테이블에 대한 신규 또는 갱싱된 통계가 있는 경우. 통계 데이터는 SQL Server 에 의해서 자동적으로 생성되거나 갱신된다. DBA 또한 CREATE STATISTICS 나 UPDATE STATISTICS 를 통해 통계데이터를 생성하거나 갱신할 수 있다. 그러나 변경된 통계 데이터가 언제나 재컴파일의 원인이 되는 건 아니다. 기본 규칙은 리컴파일을 일으킬 수 있는 데이터에 대한 변화가 있어야 한다는 것이다. Kimberly Tripp 의 블로그를 참고하여 더 자세히 알아보길 바란다.
- 누군가 프로시저에서 참조하는 쿼리에 명시된 테이블에 sp_recompile 을 수행한 경우.
Note: SQL Server 2000 에서는 recompilation 관련 구문이 존재하지 않고, 프로시저 실행시 매번 컴파일을 수행한다.
위 리스트는 결코 완전하지 않고, 리스트 중에 빠진 것을 알아차려야 한다. 바로 원래 실행과는 다르게 입력 파라메터 값이 달라진 상태로 실행하는 경우가 제외되어 있다. 아래와 같이 실행하는 것이 그 예이다.
EXEC List_orders_2 '19900101'모든 로우를 반환해야 함에도 불구하고, 이 실행은 여전히 OrderDate 에 인덱스를 사용한다. 이것을 통해 매우 중요한 사실을 깨닳아야 하는데, 바로 첫 번째 실행에 사용된 파라메터 값이 이어지는 실행 계획에 매우 큰 영향을 미친다는 것이다. 만약 첫 번째 파라메터 값이 일반적이지 않으면, 캐싱된 쿼리 실행 계획이 이후 실행되는 환경에서는 최적화되지 않은 계획이 되어버릴 가능성이 있다. 그래서 파라메터 스니핑이란 것이 매우 중요한 것이다.
Note: 실행 계획을 지워버리는 요소나 구문에 대한 모든 리스트를 보고 싶다면 아래 실행 계획 캐싱에 대한 글을 보자. Further Reading 섹션에서 볼 수 있다.
세팅이 다르면 실행 계획도 다르다.
CREATE PROCEDURE List_orders_6 AS
SELECT *
FROM Orders
WHERE OrderDate > '12/01/1998'
go
SET DATEFORMAT dmy
go
EXEC List_orders_6
go
SET DATEFORMAT mdy
go
EXEC List_orders_6
go위 SP 를 실행하면 첫 번째 실행에서 다수의 Orders 를 반환하는 것을 볼 수 있을 것이다. 반면 두 번째 실행에서는 반환 행이 0 개 이다. 그리고 실행 계획을 보면, 실행 계획도 다르다는 것을 확인할 수 있을 것이다. 첫 번째 실행에서 실행 계획은 클러스터드 인덱스 스캔이였다. ( 다수의 행을 반환하는 시나리오에서는 최고이다. ) 반면 두 번째 실행 계획에서는 Index Seek + Key Lookup 을 사용했다 ( 반환되는 행이 없을 때 좋은 플랜 ).
왜 이런 일이 발생했을까? SET DATEFORMAT 이 리컴파일의 원인일까? 아니다, 좀 더 스마트한 접근이 필요하다. 이 예제에서는 SP 실행이 순서대로 수행되었는데, 다수의 유저들이 각기 다른 Date Format 으로 동시에 실행했을 가능성이 있다. 프로시저에 대한 실행 계획이 특정 세션이나 유저에 묶이지 않는다는 사실을 기억하자, 다만 접속된 모든 유저가 공유하는 글로벌 캐싱이 있을 뿐이다. 각기 다른 실행 계획을 세운 이유는 SQL Server 가 두 번째 프로시저 실행시 두 번째 캐싱 진입점을 만들었기 때문이다. 아래 쿼리로 실행 계획을 살펴보면 이 행위를 엿볼 수 있다.
SELECT qs.plan_handle, a.attrlist
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) est
CROSS APPLY (SELECT epa.attribute + '=' + convert(nvarchar(127), epa.value) + ' '
FROM sys.dm_exec_plan_attributes(qs.plan_handle) epa
WHERE epa.is_cache_key = 1
ORDER BY epa.attribute
FOR XML PATH('')) AS a(attrlist)
WHERE est.objectid = object_id ('dbo.List_orders_6')
AND est.dbid = db_id('Northwind') Reminder: 실행 계획에 대해 해당 쿼리를 돌려서 결과를 보려면 Server state 를 볼 수 있는 서버 수준의 권한이 필요하다.
DMV ( Dynamic Management View ) sys.dm_exec_query_stats 는 현재 실행 계획 캐시에서 각 쿼리 마다 한 개씩 진입점을 지니고 있다. 만약 프로시저가 다수의 구문을 지니고 있으면 한 구문 마다 캐싱 진입점을 지니게 된다. 여기서 재미있는 것이 sql_handle 과 plan_handle 이란 것이다. 실행 계획 캐시 내에 다른 진입점을 필터링하기 위해 sql_handle 을 사용하여 어떤 프로시저를 캐싱 진입점에 매핑할 것인지 확인한다. ( 나중에 쿼리 텍스트를 받을 수 있는 예제를 볼 것이다 ) 대부분 plan_handle 을 이용하여 쿼리 실행 계획 자체를 가져오는데, 이에 대한 예제도 나중에 살펴볼 것이다. 이 예제에서는 실행 계획 속성을 알려주는 DMV 를 이용했다. 더 구체적으로 얘기하면 여기서 보이는 속성은 캐시 키 이다. 동일한 프로시저에서 하나 이상의 캐싱 진입점이 존재하면 해당 진입점은 캐싱 키가 최소한 하나 이상 다르다. 이는 SET 커맨드를 통해서 제어되지만, 전부 그런 것은 아니다.
위에서 제시한 쿼리는 두 개의 행을 리턴하는데 해당 실행 계획 캐싱에 두 가지 진입점이 있다는 것을 의미한다. 쿼리 결과는 아마 아래와 같을 것이다.
plan_handle attrlist
------------------------------- -------------------------------------------------
0x0500070064EFCA5DB8A0A90500... compat_level=100 date_first=7 date_format=1
set_options=4347 user_id=1
0x0500070064EFCA5DB8A0A80500... compat_level=100 date_first=7 date_format=2
set_options=4347 user_id=1예제를 심플하게 작성하기 위해 plan handle 값을 줄이고 attrlist 컬럼의 값을 상당 부분 삭제하고 두 줄로 축약시켰다. 해당 쿼리를 직접 실행해보면 모든 캐시 키를 볼 수 있을 것이다. 그것도 캐싱 키의 일부분일 뿐이다. sys.dm_exec_plan_attributes 에 대해 책에서 찾아보면 계획 속성에 대한 설명을 많이 볼 수 있는데, 상당히 많은 캐시 키가 문서화되지 않았음을 알게 된다. 이 챕터에서 모든 캐시 키에 대해 살펴보지는 않을 것이며, 문서화된 캐싱 키 또한 알아보지 않을 것이다. 오직 가장 중요한 캐싱 키에 대해서만 알아볼 것이다.
다시 말하지만 이 예제는 이해를 돕기 위해 만든 것이다. 그러나 Date format 차이가 왜 다른 결과를 낳은 것인지, 왜 쿼리 실행 계획이 달라질 수 밖에 없는지에 대해서 이해하기에는 좋은 예제일 것이다. 좀 더 일반적인 예제를 써보면.
EXEC sp_recompile List_orders_2
go
SET DATEFORMAT dmy
go
EXEC List_orders_2 '12/01/1998'
go
SET DATEFORMAT mdy
go
EXEC List_orders_2 '12/01/1998'
go( 최초 sp_recompile 은 이전 예제에서 생성된 캐싱 계획이 확실하게 삭제되도록 하기 위해 사용한 것이다. ) 위 예제는 동일한 결과를 뽑아주고 List_orders_6 와 마찬가지로 동일한 실행 계획을 만든다. 왜냐하면 두 쿼리 실행 계획이 실행 계획을 만드는 시점에서 동일한 파라메터 값을 사용했기 때문이다. 첫 번째 쿼리는 1998 년 1월 12일 날짜를 사용했고 두 번째는 1998년 12월 1일을 사용했다.
set_options 는 중요한 캐시 키 중 하나다. 이건 bit mask 라고 불리는데 ON / OFF 할 수 있는 SET 옵션의 수를 세팅할 수 있게 해준다. sys.dm_exec_plan_attributes 에 대한 내용을 더 찾아보면 각 비트가 설명하는 SET 옵션에 대한 세부 정보가있는 목록을 볼 수 있다. ( SET 명령에 의해 제어되지 않는 항목 또한 볼 수 있다. ) 만약 두 개의 연결에서 이러한 옵션을 다르게 설정해버리면, 동일한 프로시저에 대하여 각기 다른 캐싱 진입점을 사용하게 될 것이며 결국 다른 실행 계획을 사용하게 될 수 있다. 그리고 이로인해 성능상으로 매우 큰 차이점을 띌 수 있다. set_options 속성에 대해 알아보는 방법은 아래 쿼리를 실행시켜보는 것이다.
SELECT convert(binary(4), 4347)위 쿼리는 4347 을 Hex 값인 0x10FB 로 변경해준다. 이제 온라인 북을 보고 목록을 확인해보면 SET 옵션이 강제적으로 ANSI_PADDING, Parallel Plan, CONCAT_NULL_YIELDS_NULL, ANSI_WARNINGS, ANSI_NULLS, QUOTED IDENTIFIER, ANSI_NULL_DFLT_ON, 그리고 ARITHABORT 를 세팅 하는 것을 알 수 있다. 작성한 table-valued function 를 실행시켜볼 수도 있다.
SELECT Set_option FROM setoptions (4347) ORDER BY Set_option
Note: Parallel plan 이 동작한다고 생각할 수도 있는데 예제 자체가 병렬 처리가 아니라서 그렇게 동작하지 않는다. SQL Server 가 병렬 계획을 수립해도 CPU 를 지나치게 사용하는 경우 나중에 비정렬 계획을 수립할 수도 있다. 병렬 계획 비트가set_options 에 설정되어 있는 경우 항상 직렬 계획인것 처럼 보인다.
더 간단하게 얘기하면, ANSI_PADDING, ANSI_NULLS 같은 SET 옵션을 케시 키 그 자체라고 불러도 무방하다. 단일 숫자 값으로 더해진다는 사실은 패키징 문제일 뿐이다.
기본 세팅
Note: SET 옵션이 어떤 영향을 미치는지 궁금해 할 사람들을 위해 Book Online 을 추천한다. 어떤 책은 너무 혼란만 주는 반면, 어떤 책은 꽤 직관적으로 설명해준다. 이 포스트를 이해하는데에는 SET 옵션이 있다는 사실 자체만 알아도 충분하며, 계획 캐시에 어떤 영향을 주는지만 알면 된다.
슬프게도 Microsoft 일관성 있게 기본 값을 변경하지 않았고 심지어 오늘날에도 기본 값은 연결 방법에 따라 다르며, 아래 테이블에 자세하게 정리되어 있다.
| Applications using ADO .Net, ODBC or OLE DB | SSMS | SQLCMD, OSQL, BCP, SQL Server Agent | ISQL, DB-Library | |
|---|---|---|---|---|
| ANSI_NULL_DFLT_ON | ON | ON | ON | OFF |
| ANSI_NULLS | ON | ON | ON | OFF |
| ANSI_PADDING | ON | ON | ON | OFF |
| ANSI_WARNINGS | ON | ON | ON | OFF |
| CONACT_NULLS_YIELD_NULL | ON | ON | ON | OFF |
| QUOTED_IDENTIFIER | ON | ON | OFF | OFF |
| ARITHABORT | OFF | ON | OFF | OFF |
이 표가 무엇을 의미하는 것인지 이해할 수 있을 것이다. 어플리케이션에서 ARITHABORT OFF 상태에서 연결을 했지만 SSMS 상에서 쿼리를 실행하면 ARITHBORD 옵션은 ON 이 되어 어플리케이션이 사용하던 캐시 항목을 다시 사용하지 않는다. 그러나 SQL Server 는 현재 파라메터 값을 스니핑하며 해당 프로시저를 재컴파일하여 어플리케이션과는 다른 실행 계획을 보게될 것이다. 자 이제 이 포스트의 최초 질문에 대한 답변을 알게되었다. 다음 챕터에서는 몇 가지 가능성에 대하여 다뤄볼 것인데, 대부분의 경우 SSMS 에서는 빠르고, Application 에서는 느린 경우는 파라메터 스니핑 때문이고, ARITHABORT 에 대한 기본 값이 달라서이다. ( 이 정도로 충분한 답을 얻었다면 그만 읽어도 좋다. 그러나 성능 문제를 고치고 싶다면, 조금만 더 버텨라! 그리고 SET ARITHABORT ON 을 프로시저에서 켠다고 문제가 해결되지 않는다. )
SET 명령어와 위에서 제시한 기본 값들과 별개로, ALTER DATABASE 명령은 특정 SET 옵션을 항상 기본 값으로 ON 으로 켜둘 수 있게 해주며 따라서 API 에 의해 지정된 기본 값을 무시할 수 있다. 하지만 해당 문법이 SET 옵션에 대한 설정이 모두 가능한 것 처럼 보이지만, 옵션을 OFF 로 설정할 수는 없다. 또 명심할 것은 SSMS 에서 이 옵션을 테스트하는 경우 동작하지 않는 것 처럼 보일 수 있는데, 이는 SSMS 가 모든 기본 값을 무시하고 명시적인 SET 커맨드를 수행하기 때문이다. 동일한 목적으로 서버 레벨 세팅이 있는데, Bit mask 인 user options 이다. SSMS 에서 서버 속성에 연결 페이지에서 개별 Bit 를 설정할 수 있다. 기본적으로 이런 방식으로 기본 값을 컨트롤하는 것을 피하길 바란다, 나의 소견으론, 혼란만 가중시킬 뿐이다.
런타임 세팅만 적용되는 것은 아니다. 프로시저, 뷰, 테이블 등을 생성할 때 ANSI_NULLS 와 QUOTED_IDENTIFIER 세팅은 해당 객체와 함께 저장된다. 아래가 예인데, 이것을 실행시키면
SET ANSI_NULLS, QUOTED_IDENTIFIER OFF
go
CREATE PROCEDURE stupid @x int AS
IF @x = NULL PRINT "@x is NULL"
go
SET ANSI_NULLS, QUOTED_IDENTIFIER ON
go
EXEC stupid NULL아래 결과를 출력할 것이다.
@x is NULLQUOTED_IDENTIFIER 가 OFF 상태일 때는 " 와 ' 가 동일한 문자열 구분자가 된다. ON 상태일 때 따옴표 구분자가 대괄호와 동일하게 동작하고 PRINT 문장에서 컴파일 에러가 발생한다.
추가로 ANSI_PADDING 설정은 varchar 나 nvarchar, varbinary 같이 적용 가능한 테이블 컬럼마다 저장된다. 이러한 옵션과 각기 다른 기본 값은 정말 혼란스러운데, 쉽게 이해하기 위한 몇 가지 조언을 해보도록 하겠다. 첫번째로 7개 옵션 중 최초 6가지 옵션은 하위 호환을 위한 것이기 때문에 굳이 설정을 변경할 이유가 없다. 당연히 어떤 상황에서는 해당 옵션들을 해제하면 얻을 수 있는 약간의 편리함이 있는데, 그런 유혹에 넘어가지 않길 바란다.그러나 여기서 한 가지 복잡한 점은 SQL Server 도구가 개체를 스크립팅 할 때 이러한 옵션 중 일부에 대해 SET 명령을 실행한다는 것이다. 고맙게도 SQL Server 도구가 대부분 영향이 적은 ON 커맨드를 설정한다는 것이다. ( 하지만 테이블을 스크립트할 경우에는 ANSI_PADDING 을 마지막에 OFF 할 수도 있다. Tools -> Options -> Scripting 메뉴에서 이 옵션을 조정하여 ANSI_PADDING 을 False 로 변경할 수 있다. 개인적으로 이 방법을 추천한다 )
다음으로 ARITHABORT 관련하여 SQL 2005 또는 그 이후 버전에서 꼭 알아야 할 것이 해당 설정은 ANSI_WARNINGS 가 켜져있는 경우에는 어떠한 영향이 없다는 것이다. ( 정확하게 얘기하면 호환성 레벨이 90 이상일 때 영향이 없다는 것이다. ) 따라서 해당 옵션을 활성화 할 이유가 없다. SSMS 툴의 경우 개별적으로 조절하고 싶다면 아래 다이얼로그 창을 열어서 SET ARITHABORT 옵션을 체크 해제 할 수 있다.
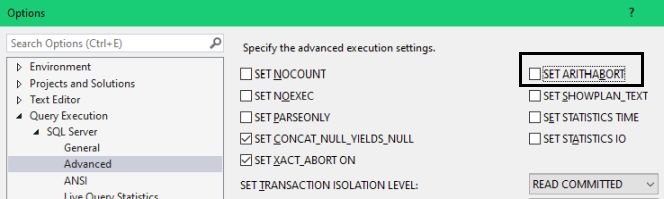
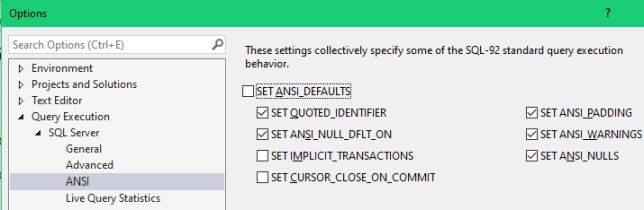
이렇게 하면 SSMS 로 접속할 때 ARITHABORT 에 대한 기본 값을 변경할 수 있다. 설정을 변경한다고 해서 어플리케이션 속도가 빨라지진 않는데, SSMS 상에서 속도 차이가 나서 당황하는 경우는 최소한 겪지 않을 것이다. 참고로 ANSI 페이지는 아래와 같은데, 절대 이 페이지에서는 아무것도 변경하지 말것을 강력히 주장하는 바이다.
SQLCMD 와 OSQL 에 대해서 얘기해보자. -l 옵션을 항상 사용하는 습관을 길러라. 이 옵션을 사용하면 SQL Server 툴에서 QUOTED_IDENTIFIER ON 상태로 실행되도록 할 수 있다. BCP 와 유사한 옵션은 -q 이다. 이건 Agent 에서 좀 더 어려운데, 적어도 내가 아는 한 Agent 에 대한 기본 값을 변경할 방법이 전혀 없기 때문이다. 그럼 다시 저장 프로시저만 실행하는 환경이라면, 저장된 세팅을 선행하여 사용하기 때문에 이것은 전혀 문제가되지 않는다. 그러나 Agent 를 통해서 SQL 배치를 수행하는 경우라면 QUOTED_IDENTIFIER 의 다른 기본 값으로 인해 SSMS 나 Agent 에서 쿼리 실행 계획이 달라져서 이 문제에 직면할 수 있다.
SET DATEFORMAT 에 대해 살펴보았고, 2가지 옵션이 있다는 것도 알고 있다. 바로 LANGUAGE 와 DATEFIRST 이다. 기본 언어 세팅은 유저마다 설정되고 서버 구성 옵션도 있는데 새로운 유저에 대해 어떤 언어를 사용할 것인지 제어하게된다. 기본 언어는 다른 두개 언어에 대한 기본 설정을 제어한다. 언어는 캐시 키 이기 때문에 다른 언어를 사용하는 두 명의 유저가 다른 캐시 항목을 지니게 됨을 의미하며 별도의 쿼리 실행 계획으로 실행될 수 있음을 의미한다.
내가 추천하는 것은 언어와 날짜 설정에 의존하지 않도록 하는 것이다. 날짜 문자열을 사용하는 경우라면 언제나 yyyyMMdd 같은 형식으로 해석될 수 있는 동일한 형식을 사용하는 것이 그 예이다. ( 날짜 형식에 대해 더 자세히 알고 싶다면 SQL Server MVP Tibor Karaszi 가 작성한 The ultimate guide to the datetime datatypes 를 읽어보길 권한다. ) 유저 설정 언어에 따라 저장 프로시저에서 로컬라이징된 날짜 형식이 필요한 경우 SQL Server 언어 설정에 의존하기 보단, 해당 변환 작업을 직접 작성하는 것이 낫다.
Note: ARITHABORT 가 ANSI_WARNINGS 가 ON 상태인 경우 아무런 영향이 없다고 언급했었다. 그러나 SET ARITHABORT ON 은 이런 메시지를 보여주는데 " ARITHABORT 를 로그온시 항상 활성화해야 합니다. ARITHABORT 를 비활성화 하는 경우 쿼리 최적화에 부정적인 영향을 미쳐 성능 이슈로 이어질 수 있습니다. " 이 문제에 대해 과거 SQL Server 버전에서 확인해보았는데, 아주 틀린 얘기라고는 할 수 없었다. 이 메시지는 SQL Server 2012 버전에서 처음 등장했다. 옵티마이저 내부는 나 또한 모르는 관계로, 이 메시지가 잘못되었다고 말할 수는 없지만, 적어도 나에게는 틀린 얘기이다. 그래서 여전히 호환성 레벨 90 또는 그 이상에서 ARITHABORT 설정은 성능 이슈와는 전혀 관련없다는 말은 유효하다. SQL Server 에서 권고하는 사항에 대해서 따라야겠다 느낀다면 매번 접속할 때 마다 실행되는 추가적인 배치 작업을 수행하는 경우 네트워크 라운드트립이 더 발생해서 그 자체만으로 성능 이슈에 영향이 생길 수 있다는 사실을 기억하자.
Recompile 이 주는 영향
CREATE PROCEDURE List_orders_7 @fromdate datetime,
@ix bit AS
SELECT @fromdate = dateadd(YEAR, 2, @fromdate)
SELECT * FROM Orders WHERE OrderDate > @fromdate
IF @ix = 1 CREATE INDEX test ON Orders(ShipVia)
SELECT * FROM Orders WHERE OrderDate > @fromdate
go
EXEC List_orders_7 '19980101', 1위 쿼리를 실행하고 실제 실행 계획을 살펴보면 첫 번째 SELECT 는 이제까지 배운데로 Clustered Index Scan 이다. SQL Server 가 1998-01-01 값을 받아서 이 쿼리가 267 개 행을 반환할 것이라 예측했는데, Index Seek 과 Key Lookup 으로 읽기에는 너무나 많은 행이다. SQL Server 가 모르는 것은 쿼리 실행 전 @fromdate 의 변화이다. 그럼에도 불구하고 두 번째 쿼리의 실행 계획 또한 동일하게 Index Seek + Key lookup 이고, 예상 반환 행 수는 한 개이다. CREATE INDEX 으로 인해 Orders 테이블 스키마가 변경되었다고 마킹되었기 때문이다. 그리하여 두 번째 SELECT 는 재컴파일되었다. 쿼리 문을 재컴파일할 때 SQL Server 는 파라메터 값을 조사하고 더 좋은 쿼리 실행 계획을 찾는다. 이 프로시저를 다른 파라메터 값으로 다시 수행해보자.
EXEC List_orders_7 '19960101', 0이 실행 계획은 첫 번째 실행과 동일한데, 보기보다 흥미롭다. 이 쿼리를 두 번쨰로 실행하면 첫 번째 쿼리는 추가된 인덱스로 인하여 재컴파일 되야하는데, 이번에는 스캔이 올바른 실행 계획이 된다. 왜냐하면 Orders 테이블의 3/1 을 리턴받기 때문이다. 그러나 두 번째 쿼리가 재컴파일되지 않기 때문이 두 번째 쿼리는 Index Seek 으로 실행된다. 더 이상 Index Seek 은 효율적인 계획이 아님에도 말이다. 테스트를 계속하기 전에 아래와 같이 클린업을 진행하자.
DROP INDEX test ON Orders
DROP PROCEDURE List_orders_7앞서 밝혔 듯 이 샘플은 테스트를 위해 만든 것이다. 간단히 실행될 수 있으면서도 모든 것을 커버하는 테스트 쿼리를 작성하고 싶었다. 실전에선 다른 테이블을 대상으로하는 두 개의 쿼리에서 동일한 파라메터를 사용하는 프로시저를 사용할 것이다. DBA 는 테이블 중 하나에 새로운 인덱스를 생성할 것이고, 이것이 한 테이블에 대한 쿼리를 재컴파일하게 만들고, 다른 테이블에 대한 쿼리에 대해선 재컴파일을 하지 않는다. 반드시 알고 가야 할 사항은 프로시저 내에 두 문장에 대한 쿼리 실행 계획이 스니프된 파라메터 값으로 인해 컴파일되었다는 사실이다. 이런 상황에선 지역 변수로써 값을 사용해야 할 것 같아보이지만, 그렇지 않다.
CREATE PROCEDURE List_orders_8 AS
DECLARE @fromdate datetime
SELECT @fromdate = '20000101'
SELECT * FROM Orders WHERE OrderDate > @fromdate
CREATE INDEX test ON Orders(ShipVia)
SELECT * FROM Orders WHERE OrderDate > @fromdate
DROP INDEX test ON Orders
go
EXEC List_orders_8
go
DROP PROCEDURE List_orders_8이 예제에서 Clustered Index Scan 가 두 셀렉트 문에서 사용되었는데 두 번째 셀렉트가 실행 중에 @fromdate 값을 알고 있는 상태임에도 Clustered Index 가 사용되었다. 한 가지 예외 사항이 있는데, 테이블 변수라는 것이 그 예외이다. 일반적으로 SQL Server 는 테이블 변수가 1개의 행을 지니고 있을 것이라 예측하는데, 재컴파일이 수행되는 경우 예측수치는 달라질 수 있다.
CREATE PROCEDURE List_orders_9 AS
DECLARE @ids TABLE (a int NOT NULL PRIMARY KEY)
INSERT @ids (a)
SELECT OrderID FROM Orders
SELECT COUNT(*)
FROM Orders O
WHERE EXISTS (SELECT *
FROM @ids i
WHERE O.OrderID = i.a)
CREATE INDEX test ON Orders(ShipVia)
SELECT COUNT(*)
FROM Orders O
WHERE EXISTS (SELECT *
FROM @ids i
WHERE O.OrderID = i.a)
DROP INDEX test ON Orders
go
EXEC List_orders_9
go
DROP PROCEDURE List_orders_9위 코드를 실행하는 경우 총 4개의 실행 계획을 볼 수 있따. 흥미로운 두 가지는 두 번째 쿼리와 4번째 쿼리이며 모두 동일한 SELECT COUNT(*) 쿼리를 포함한다. 여기서 흥미로운 부분을 테이블 변수에 대한 Clustered Index Scan 연산자의 팝업과 함께 포함 시켰다.
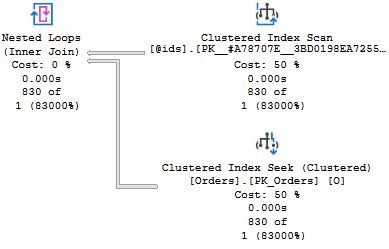
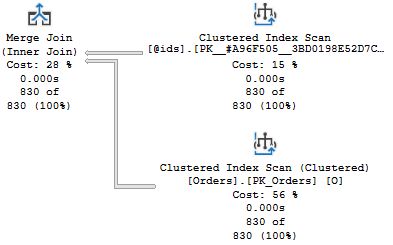
첫 번째 실행 계획에서 Nested Loops Join 연산자가 클러스터드 인덱스 스캔을 Orders 테이블 대상으로 수행했다. 그리고 테이블 변수에 존재하는 행 예상 수치와 동일하다. 바로 1개의 행을 리턴할 것이라 예측하는 기본 예측치이다. 두 번째 쿼리에서 Join 은 Merge Join 과 함께 테이블 스캔으로 수행되었다. 위에서 볼 수 있 듯 테이블 변수에 대한 예측치는 이제 830 행인데, SQL Server 가 쿼리를 재컴파일 할 때 테이블 변수의 카디널리티를 확인하기 때문이다. 파라메터 변수가 아님에도, 이런 일이 발생한다.
그리고 운에 따라 파라메터 스니핑과 비슷한 이슈가 발생할 수 있다. 시스템의 핵심 프로시저가 갑자기 느려진 경우를 맞닥드린적 있는데, 이 때 41개 행을 반환할 것으로 예측한 테이블 변수와 함께 SQL 한 구문을 추적해보았는데, 안타깝게도 이 프로시저가 실행될 때 순차적으로 한번 씩 실행됐던 것을 생각하면 1개 행을 리턴하는 Index Seek + Key lookup 이 더 좋다. 테이블 변수가 나왔으니 테이블 벨류 파라메터에 대해 궁금점이 있을 수 있다. TVP 는 SQL 2008 에서 도입되었다. TVP 는 테이블 변수와 매우 유사하게 처리되는데, TVP 가 프로시저가 수행되기 전에 처리되는 관계로 SQL Server 가 1개 이상의 행을 리턴하는 것으로 예측하는 것은 일반적인 일이 되었다.
CREATE TYPE temptype AS TABLE (a int NOT NULL PRIMARY KEY)
go
CREATE PROCEDURE List_orders_10 @ids temptype READONLY AS
SELECT COUNT(*)
FROM Orders O
WHERE EXISTS (SELECT *
FROM @ids i
WHERE O.OrderID = i.a)
go
DECLARE @ids temptype
INSERT @ids (a)
SELECT OrderID FROM Orders
EXEC List_orders_10 @ids
go
DROP PROCEDURE List_orders_10
DROP TYPE temptype해당 이 프로시저의 쿼리 실행 계획은 List_orders_9 의 두 번째 셀렉트 쿼리 실행 계획과 동일하다. 이 계획에선 Merge Join 과 클러스터드 인덱스 스캔이 Orders 테이블 대상으로 수행되는데 SQL Server 가 쿼리가 컴파일될 때 @ids 에서 830개의 행을 확인했기 때문이다.
The story so far
SET ARITHABORT OFF이로써 매우 비슷한 현상을 SSMS 에서도 볼 수 있다. ARITHABORT 에 대한 변화가 일어나면 파라메터 스니핑과 관련된 성능 이슈가 발생할 수 있다. 아직 모르고 있는 사실은 이 성능 문제를 어떻게 설명할 것이냐인데, 다음 챕터에서 컴파일 가능한 해결책들에 대해 얘기해볼 것이다. 우리가 아직 알지 못하는 것은 이 성능 문제를 해결하는 방법이며, 다음 장에서 컴파일의 주제로 돌아 가기 전에 가능한 해결책에 대해 이야기 해 볼 것이다. 이번 챕터에서는 임시 쿼리 (ad-hoc queries)를 위한 동적 SQL 을 다뤄 본 것이다.
Note: 이상한 현상은 언제나 발생한다. 내가 주로 작업하는 어플리케이션에서는 접속할 때 마다 ARITHABORT ON 을 실제로 수행하여 SSMS 과 다른 성능이 발생하는 혼란스러운 현상을 애초에 차단하고 있다. 어플리케이션의 몇몇 부분은 SET NO_BROWSETABLE ON 을 연결시 지정하는데, 문서화되지 않은 SET 커맨드의 영향에 대해서는 아는 바가 없지만 Classic ADO 의 초창기 버전과 관련이 있을 수 있음을 떠올려보긴 한다. 물론 이 또한 캐싱 키이다.
Slow in the Application, Fast in SSMS? Part 2
Putting the query plan into the cache.
- SQL Server's buffer cache is fully utilised, and SQL Server needs to age out buffers that have not been used for some time from the cache. The buffer cache includes table data as well as query plans.
- Someone runs ALTER PROCEDURE on the procedure.
- Someone runs sp_recompile on the procedure.
- Someone runs the command DBCC FREEPROCCACHE which clears the entire plan cache.
- SQL Server is restarted. Since the cache is memory-only, the cache is not preserved over restarts.
- Changing of certain configuration parameters (with sp_configure or through the Server Properties pages in SSMS) evicts the entire plan cache.
If such an event occurs, a new query plan will be created the next time the procedure is executed. SQL Server will anew "sniff" the input parameters, and if the parameter values are different this time, the new query plan may be different from the previous plan.
There are other events that do not cause the entire procedure plan to be evicted from the cache, but which trigger recompilation of one or more individual statements in the procedure. The recompilation occurs the next time the statement is executed. This applies even if the event occurred after the procedure started executing. Here are examples of such events:
- Changing the definition of a table that appears in the statement.
- Dropping or adding an index for a table appearing in the statement. This includes rebuilding an index with ALTER INDEX or DBCC DBREINDEX.
- New or updated statistics for a table in the statement. Statistics can be created and updated by SQL Server automatically. The DBA can also create and update statistics with the commands CREATE STATISTICS and UPDATE STATISTICS. However, changed statistics do not always cause recompilation. The basic rule is that there should have been a change in the data for recompilation to be triggered. See this blog post from Kimberly Tripp for more details.
- Someone runs sp_recompile on a table referred to in the statement.
Note: In SQL Server 2000, there is no statement recompilation, but the entire procedure is always recompiled.
These lists are by no means exhaustive, but you should observe one thing which is not there: executing the procedure with different values for the input parameters from the original execution. That is, if the second invocation of List_orders_2 is:
EXEC List_orders_2 '19900101'The execution will still use the index on OrderDate, despite the query now retrieves all orders. This leads to a very important observation: the parameter values of the first execution of the procedure have a huge impact for subsequent executions. If this first set of values for some reason is atypical, the cached plan may not be optimal for future executions. This is why parameter sniffing is such a big deal.
Note: for a complete list of what can cause plans to be flushed or statements to be recompiled, see the white paper on Plan Caching listed in the Further Reading section.
Different plans for different settings.
There is a plan for the procedure in the cache. That means that everyone can use it, or? No, in this section we will learn that there can be multiple plans for the same procedure in the cache. To understand this, let's consider this contrived example:
CREATE PROCEDURE List_orders_6 AS
SELECT *
FROM Orders
WHERE OrderDate > '12/01/1998'
go
SET DATEFORMAT dmy
go
EXEC List_orders_6
go
SET DATEFORMAT mdy
go
EXEC List_orders_6
goIf you run this, you will notice that the first execution returns many orders, whereas the second execution returns no orders. And if you look at the execution plans, you will see that they are different as well. For the first execution, the plan is a Clustered Index Scan (which is the best choice with so many rows returned), whereas the second execution plan uses Index Seek with Key Lookup (which is the best when no rows are returned).
How could this happen? Did SET DATEFORMAT cause recompilation? No, that would not be smart. In this example, the executions come one after each other, but they could just as well be submitted in parallel by different users with different settings for the date format. Keep in mind that the entry for a stored procedure in the plan cache is not tied to a certain session or user, but it is global to all connected users.
Instead the answer is that SQL Server creates a second cache entry for the second execution of the procedure. We can see this if we peek into the plan cache with this query:
SELECT qs.plan_handle, a.attrlist
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) est
CROSS APPLY (SELECT epa.attribute + '=' + convert(nvarchar(127), epa.value) + ' '
FROM sys.dm_exec_plan_attributes(qs.plan_handle) epa
WHERE epa.is_cache_key = 1
ORDER BY epa.attribute
FOR XML PATH('')) AS a(attrlist)
WHERE est.objectid = object_id ('dbo.List_orders_6')
AND est.dbid = db_id('Northwind') Reminder: You need the server-level permission VIEW SERVER STATE to run queries against the plan cache.
The DMV (Dynamic Management View) sys.dm_exec_query_stats has one entry for each query currently in the plan cache. If a procedure has multiple statements, there is one row per statement. Of interest here is sql_handle and plan_handle. I use sql_handle to determine which procedure the cache entry relates to (later we will see examples where we also retrieve the query text) so that we can filter out all other entries in the cache.
Most often you use plan_handle to retrieve the query plan itself, and we will see an example of this later, but in this query I access a DMV that returns the attributes of the query plan. More specifically, I return the attributes that are cache keys. When there is more than one entry in the cache for the same procedure, the entries have at least one difference in the cache keys. A cache key is a run-time setting, which for one reason or another calls for a different query plan. Most of these settings are controlled with a SET command, but not all.
The query above returns two rows, indicating that there are two entries for the procedure in the cache. The output may look like this:
plan_handle attrlist
------------------------------- -------------------------------------------------
0x0500070064EFCA5DB8A0A90500... compat_level=100 date_first=7 date_format=1
set_options=4347 user_id=1
0x0500070064EFCA5DB8A0A80500... compat_level=100 date_first=7 date_format=2
set_options=4347 user_id=1To save space, I have abbreviated the plan handles and deleted many of the values in the attrlist column. I have also folded that column into two lines. If you run the query yourself, you can see the complete list of cache keys, and they are quite a few of them. If you look up the topic for sys.dm_exec_plan_attributes in Books Online, you will see description for many of the plan attributes, but you will also note that far from all cache keys are documented. In this article, I will not dive into all cache keys, not even the documented ones, but focus only on the most important ones.
As I said, the example is contrived, but it gives a good illustration to why the query plans must be different: different date formats may yield different results. A somewhat more normal example is this:
EXEC sp_recompile List_orders_2
go
SET DATEFORMAT dmy
go
EXEC List_orders_2 '12/01/1998'
go
SET DATEFORMAT mdy
go
EXEC List_orders_2 '12/01/1998'
go(The initial sp_recompile is to make sure that the plan from the previous example is flushed.) This example yields the same results and the same plans as with List_orders_6 above. That is, the two query plans use the actual parameter value when the respective plan is built. The first query uses 12 Jan 1998, and the second 1 Dec 1998.
A very important cache key is set_options. This is a bit mask that gives the setting of a number of SET options that can be ON or OFF. If you look further in the topic of sys.dm_exec_plan_attributes, you find a listing that details which SET option each bit describes. (You will also see that there are a few more items that are not controlled by the SET command.) Thus, if two connections have any of these options set differently, the connections will use different cache entries for the same procedure – and therefore they could be using different query plans, with possibly big difference in performance.
One way to translate the set_options attribute is to run this query:
SELECT convert(binary(4), 4347)This tells us that the hex value for 4347 is 0x10FB. Then we can look in Books Online and follow the table to find out that the following SET options are in force: ANSI_PADDING, Parallel Plan, CONCAT_NULL_YIELDS_NULL, ANSI_WARNINGS, ANSI_NULLS,QUOTED_IDENTIFIER, ANSI_NULL_DFLT_ON and ARITHABORT. You can also use this table-valued function that I have written and run:
SELECT Set_option FROM setoptions (4347) ORDER BY Set_optionNote: You may be wondering what Parallel Plan is doing here, not the least since the plan in the example is not parallel. When SQL Server builds a parallel plan for a query, it may later also build a non-parallel plan if the CPU load in the server is such that it is not defensible to run a parallel plan. It seems that for a plan that is always serial that the bit for parallel plan is nevertheless set in set_options.
To simplify the discussion, we can say that each of these SET options – ANSI_PADDING, ANSI_NULLS etc – is a cache key on its own. The fact that they are added together in a singular numeric value is just a matter of packaging.
The default settings
About all of the SET ON/OFF options that are cache keys exist because of legacy reasons. Originally, in the dim and distant past, SQL Server included a number of behaviours that violated the ANSI standard for SQL. With SQL Server 6.5, Microsoft introduced all these SET options (save for ARITHABORT, which was in the product already in 4.x), to permit users to use SQL Server in an ANSI-compliant way. In SQL 6.5, you had to use the SET options explicitly to get ANSI compliance, but with SQL 7, Microsoft changed the defaults for clients that used the new versions of the ODBC and OLE DB APIs. The SET options still remained to provide backwards compatibility for older clients.
Note: In case you are curious what effect these SET options have, I refer you to Books Online. Some of them are fairly straight-forward to explain, whereas others are just too confusing. To understand this article, you only need to understand that they exist, and what impact they have on the plan cache.
Alas, Microsoft did not change the defaults with full consistency, and even today the defaults depend on how you connect, as detailed in the table below.
| Applications using ADO .Net, ODBC or OLE DB | SSMS | SQLCMD, OSQL, BCP, SQL Server Agent | ISQL, DB-Library | |
|---|---|---|---|---|
| ANSI_NULL_DFLT_ON | ON | ON | ON | OFF |
| ANSI_NULLS | ON | ON | ON | OFF |
| ANSI_PADDING | ON | ON | ON | OFF |
| ANSI_WARNINGS | ON | ON | ON | OFF |
| CONACT_NULLS_YIELD_NULL | ON | ON | ON | OFF |
| QUOTED_IDENTIFIER | ON | ON | OFF | OFF |
| ARITHABORT | OFF | ON | OFF | OFF |
You might see where this is getting at. Your application connects with ARITHABORT OFF, but when you run the query in SSMS, ARITHABORT is ON and thus you will not reuse the cache entry that the application uses, but SQL Server will compile the procedure anew, sniffing your current parameter values, and you may get a different plan than from the application. So there you have a likely answer to the initial question of this article. There are a few more possibilities that we will look into in the next chapter, but by far the most common reason for slow in the application, fast in SSMS is parameter sniffing and the different defaults for ARITHABORT. (If that was all you wanted to know, you can stop reading. If you want to fix your performance problem – hang on! And, no, putting SET ARITHABORT ON in the procedure is not the solution.)
Besides the SET command and the defaults above, ALTER DATABASE permits you to say that a certain SET option always should be ON by default in a database and thus override the default set by the API. However, while the syntax may indicate so, you cannot specify than an option should be OFF this way. Also, beware that if you test these options from Management Studio, they may not seem to work, since SSMS submits explicit SET commands, overriding any default. There is also a server-level setting for the same purpose, the configuration option user options which is a bit mask. You can set the individual bits in the mask from the Connection pages of the Server Properties in Management Studio. Overall, I recommend against controlling the defaults this way, as in my opinion they mainly serve to increase the confusion.
It is not always the run-time setting of an option that applies. When you create a procedure, view, table etc, the settings for ANSI_NULLS and QUOTED_IDENTIFIER, are saved with the object. That is, if you run this:
SET ANSI_NULLS, QUOTED_IDENTIFIER OFF
go
CREATE PROCEDURE stupid @x int AS
IF @x = NULL PRINT "@x is NULL"
go
SET ANSI_NULLS, QUOTED_IDENTIFIER ON
go
EXEC stupid NULLIt will print
@x is NULL(When QUOTED_IDENTIFIER is OFF, double quote(") is a string delimiter on equal basis with single quote('). When the setting is ON, double quotes delimit identifiers in the same way that square brackets ([]) do and the PRINT statement would yield a compilation error.)
In addition, the setting for ANSI_PADDING is saved per table column where it is applicable (The data types varchar, nvarchar and varbinary).
All these options and different defaults are certainly confusing, but here are some pieces of advice. First, remember that the first six of these seven options exist only to supply backwards compatibility, so there is little reason why you should ever have any of them OFF. Yes, there are situations when some of them may seem to buy a little more convenience if they are OFF, but don't fall for that temptation. One complication here, though, is that the SQL Server tools spew out SET commands for some of these options when you script objects. Thankfully, they mainly produce SET ON commands that are harmless. (But when you script a table, scripts may still in have a SET ANSI_PADDING OFF at the end. You can control this under Tools->Options->Scripting where you can set Script ANSI_PADDING commands to False, which I recommend.)
Next, when it comes to ARITHABORT, you should know that in SQL 2005 and later versions, this setting has zero impact as long as ANSI_WARNINGS is ON. (To be precise: it has no impact as long as the compatibility level is 90 or higher.) Thus, there is no reason to turn it on for the sake of the matter. And when it comes to SQL Server Management Studio, you might want do yourself a favour, and open this dialog and uncheck SET ARITHABORT as highlighted:
This will change your default setting for ARITHABORT when you connect with SSMS. It will not help you to make your application to run faster, but you will at least not have to be perplexed by getting different performance in SQL Server Management Studio. For reference, below is how the ANSI page should look like. A very strong recommendation: never change anything on this page!
When it comes to SQLCMD and OSQL, make the habit to always use the -I option, which causes these tools to run with QUOTED_IDENTIFIER ON. The corresponding option for BCP is -q. It's a little more difficult in Agent, since there is no way to change the default for Agent – at least I have not found any. Then again, if you only run stored procedures from your job steps, this is not an issue, since the saved setting for stored procedures takes precedence. But if you would run loose batches of SQL from Agent jobs, you could face the problem with different query plans in the job and SSMS because of the different defaults for QUOTED_IDENTIFER. For such jobs, you should always include the command SET QUOTED_IDENTIFIER ON as the first command in the job step.
We have already looked at SET DATEFORMAT, and there are two more options in that group: LANGUAGE and DATEFIRST. The default language is configured per user, and there is a server-wide configuration option which controls what is the default language for new users. The default language controls the default for the other two. Since they are cache keys, this means that two users with different default languages will have different cache entries, and may thus have different query plans.
My recommendation is that you should try to avoid being dependent on language and date settings in SQL Server altogether. For instance, in as far as you use date literals at all, use a format that is always interpreted the same, such as YYYYMMDD. (For more details about date formats, see the article The ultimate guide to the datetime datatypes by SQL Server MVP Tibor Karaszi.) If you want to produce localised output from a stored procedure depending on the user's preferred language, it may be better to roll your own than rely on the language setting in SQL Server.
Note: I said above that ARITHABORT has no impact at all as long as ANSI_WARNINGS is on. Yet, the topic for SET ARITHABORT ON has this passage: You should always set ARITHABORT to ON in your logon sessions. Setting ARITHABORT to OFF can negatively impact query optimization leading to performance issues. I have checked older versions of this topic, and the passage first appeared in the SQL 2012 version of the topic. Since I don't know the optimizer internals, I can't say for sure the passage is nonsense, but it certainly does not make sense to me. Thus, I stand to what I said above: the setting has zero impact on compatibility level 90 and higher. I you feel compelled to follow the recommendation, please bear in mind that if start to submit an extra batch for every connection you make, you will add an extra network roundtrip, which can be a performance issue in itself.
The effects of statement recompile
To get a complete picture how SQL Server builds the query plan, we need to study what happens when individual statements are recompiled. Above, I mentioned a few situations where it can happen, but at that point I did not go into details.
The procedure below is certainly contrived, but it serves well to demonstrate what happens.
CREATE PROCEDURE List_orders_7 @fromdate datetime,
@ix bit AS
SELECT @fromdate = dateadd(YEAR, 2, @fromdate)
SELECT * FROM Orders WHERE OrderDate > @fromdate
IF @ix = 1 CREATE INDEX test ON Orders(ShipVia)
SELECT * FROM Orders WHERE OrderDate > @fromdate
go
EXEC List_orders_7 '19980101', 1When you run this and look at the actual execution plan, you will see that the plan for the first SELECT is a Clustered Index Scan, which agrees with what we have learnt this far. SQL Server sniffs the value 1998-01-01 and estimates that the query will return 267 rows which is too many to read with Index Seek + Key Lookup. What SQL Server does not know is that the value of @fromdate changes before the queries are executed. Nevertheless, the plan for the second, identical, query is precisely Index Seek + Key Lookup and the estimate is that one row is returned. This is because the CREATE INDEX statement sets a mark that the schema of the Orders table has changed, which triggers a recompile of the second SELECT statement. When recompiling the statement, SQL Server sniffs the value of the parameter which is current at this point, and thus finds the better plan.
Run the procedure again, but with different parameters (note that the date is two years earlier in time):
EXEC List_orders_7 '19960101', 0The plans are the same as in the first execution, which is a little more exciting than it may seem at first glance. On this second execution, the first query is recompiled because of the added index, but this time the scan is the "correct" plan, since we retrieve about one third of the orders. However, since the second query is not recompiled now, the second query runs with the Index Seek from the previous execution, although now it is not an efficient plan. Before you continue, clean up:
DROP INDEX test ON Orders
DROP PROCEDURE List_orders_7As I said, this example is contrived. I made it that way, because I wanted a compact example that is simple to run. In a real-life situation, you may have a procedure that uses the same parameter in two queries against different tables. The DBA creates a new index on one of the tables, which causes the query against that table to be recompiled, whereas the other query is not. The key takeaway here is that the plans for two statements in a procedure may have been compiled for different "sniffed" parameter values.
When we have seen this, it seems logical that this could be extended to local variables as well. But this is not the case:
CREATE PROCEDURE List_orders_8 AS
DECLARE @fromdate datetime
SELECT @fromdate = '20000101'
SELECT * FROM Orders WHERE OrderDate > @fromdate
CREATE INDEX test ON Orders(ShipVia)
SELECT * FROM Orders WHERE OrderDate > @fromdate
DROP INDEX test ON Orders
go
EXEC List_orders_8
go
DROP PROCEDURE List_orders_8In this example, we get a Clustered Index Scan for both SELECT statements, despite that the second SELECT is recompiled during execution and the value of @fromdate is known at this point. However, there is one exception, and that is table variables. Normally SQL Server estimates that a table variable has a single row, but when there are recompiles in sway, the estimate may be different:
CREATE PROCEDURE List_orders_9 AS
DECLARE @ids TABLE (a int NOT NULL PRIMARY KEY)
INSERT @ids (a)
SELECT OrderID FROM Orders
SELECT COUNT(*)
FROM Orders O
WHERE EXISTS (SELECT *
FROM @ids i
WHERE O.OrderID = i.a)
CREATE INDEX test ON Orders(ShipVia)
SELECT COUNT(*)
FROM Orders O
WHERE EXISTS (SELECT *
FROM @ids i
WHERE O.OrderID = i.a)
DROP INDEX test ON Orders
go
EXEC List_orders_9
go
DROP PROCEDURE List_orders_9When you run this, you will get in total four execution plans. The two of interest are the second and fourth plans that come from the two identical SELECT COUNT(*) queries. I have included the interesting parts of the plans here, together with the pop-up for the Clustered Index Scan operator over the table variable.
In the first plan, there is a Nested Loops Join operator together with a Clustered Index Seek on the Orders table, which is congruent with the estimate of the number of rows in the table variable: one single row, the standard assumption. In the second query, the join is carried out with a Merge Join together with a table scan of Orders. As you can see, the estimate for the table variable is now 830 rows, because when recompiling a query, SQL Server "sniffs" the cardinality of the table variable, even if it is not a parameter.
And with some amount of bad luck this can cause issues similar to those with parameter sniffing. I once ran into a situation where a key procedure in our system suddenly was slow, and I tracked it down to a statement with a table variable where the estimated number of rows was 41. Unfortunately, when this procedure runs in the daily processing it's normally called on one-by-one basis, so one row was a much better estimate in that case.
Speaking of table variables, you may be curious about table-valued parameters, introduced in SQL 2008. They are handled very similar to table variables, but since the parameter is populated before the procedure is invoked, it is now a common situation that SQL Server will use an estimate of more than one row. Here is an example:
CREATE TYPE temptype AS TABLE (a int NOT NULL PRIMARY KEY)
go
CREATE PROCEDURE List_orders_10 @ids temptype READONLY AS
SELECT COUNT(*)
FROM Orders O
WHERE EXISTS (SELECT *
FROM @ids i
WHERE O.OrderID = i.a)
go
DECLARE @ids temptype
INSERT @ids (a)
SELECT OrderID FROM Orders
EXEC List_orders_10 @ids
go
DROP PROCEDURE List_orders_10
DROP TYPE temptypeThe query plan for this procedure is the same as for the second SELECT query in List_orders_9, that is Merge Join + Clustered Index Scan of Orders, since SQL Server sees the 830 rows in @ids when the query is compiled.
The story so far
In this chapter, we have looked at how SQL Server compiles a stored procedure and what significance the actual parameter values have for compilation. We have seen that SQL Server puts the plan for the procedure into cache, so that the plan can be reused later. We have also seen that there can be more than one entry for the same stored procedure in the cache. We have seen that there is a large number of different cache keys, so potentially there can be very many plans for a single stored procedure. But we have also learnt that many of the SET options that are cache keys are legacy options that you should never change.
In practice, the most important SET option is ARITHABORT, because the default for this option is different in an application and in SQL Server Management Studio. This explains why you can spot a slow query in your application, and then run it at good speed in SSMS. The application uses a plan which was compiled for a different set of sniffed parameter values than the actual values, whereas when you run the query in SSMS, it is likely that there is no plan for ARITHABORT ON in the cache, so SQL Server will build a plan that fits with your current parameter values.
You have also understood that you can verify that this is the case by running this command in your query window:
SET ARITHABORT OFFand with great likelihood, you will now get the slow behaviour of the application also in SSMS. If this happens, you know that you have a performance problem related to parameter sniffing. What you may not know yet is how to address this performance problem, and in the following chapters I will discuss possible solutions, before I return to the theme of compilation, this time for ad-hoc queries, a.k.a. dynamic SQL.
Note: There are always these funny variations. The application I mainly work with actually issues SET ARITHABORT ON when it connects, so we should never see this confusing behaviour in SSMS. Except that we do. Some part of the application also issues the command SET NO_BROWSETABLE ON on connection. I have never been able to understand the impact of this undocumented SET command, but I seem to recall that it is related to early versions of "classic" ADO. And, yes, this setting is a cache key.
'SQLServer' 카테고리의 다른 글
| Slow in the Application, Fast in SSMS? Part 1 (0) | 2018.07.19 |
|---|---|
| SQL SERVER ERROR 18456 (0) | 2017.11.24 |